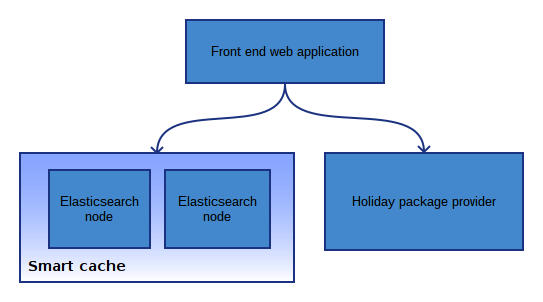
A novel use of Elasticsearch in the context of holiday search, not as a traditional store of persistent documents, but as a rolling cache of transient holiday packages. This puts unique demands on Elasticsearch in terms of index and deletion rate, concurrent to a high query rate.
Figures below are from February 2014, so will have changed.
Fancy a holiday?
The travel industry works around the principal of ‘dynamic packaging’ of holidays. When you search for a holiday from any London airport to the Caribbean in a 4+ star hotel, separate databases of flight availability and hotel availability are combined to produce an up to the minute ‘package’ meeting your requested criteria.
These are big databases and packaging is an expensive operation. Caching it is key to offering best performance and user experience, but since these results are based on constantly changing availability they must be expired within a relatively short time.
We were replacing a slow legacy system which ran on an eye-watering amount of EC2 hardware. There was a basic cache in this system, but only on exact searches – resulting in a poor cache hit ratio, and a big chunk of memory wasted to an ineffective cache. When the cache missed, users ended up waiting seconds for results. Not a great experience.
The aim was to build something faster, cheaper to run and improve cache hit ratio, by making the cache smarter. And implement redundancy – the existing system had a single cache server – a big single point of failure!
Step up Elasticsearch.
Cutting down the Amazon bill
The existing system was running on a big expensive box: a Windows m2.2xlarge costing $503 / month (over 1 year reserved), the replacement cache of the new system runs on 2x c3.large, running at $160 / month (again 1 year reserved), with more than enough overhead in capacity over the existing system to implement redundancy.
So a very decent saving, both on hardware costs and licensing moving entirely to open source.
Aside: c3.large instances are the bees knees. They’re the best bang for the buck in terms of CPU power, and come with a pair of local 16GB SSDs for storage. Elasticsearch flies on a RAID1 array of these.
Initial numbers
The system has only just rolled out to production traffic, and we’re still tweaking, but initial numbers look very good.
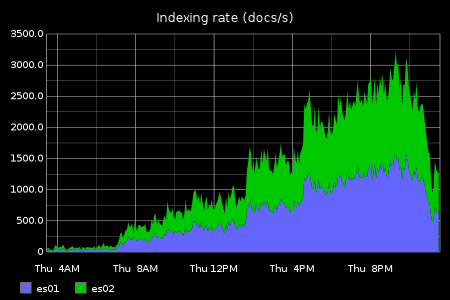
Elasticsearch peaked indexing at 3000 docs/s, and over a full 24 hours indexed a total of 100m documents. Every one of these becoming a delete after 15 minutes, so a high deletion rate too.
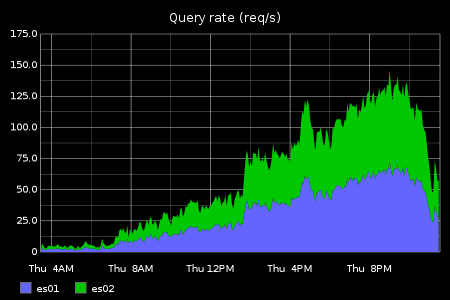
At the peak it was being hit with a qps of 140/s, served with an average latency of 35ms.
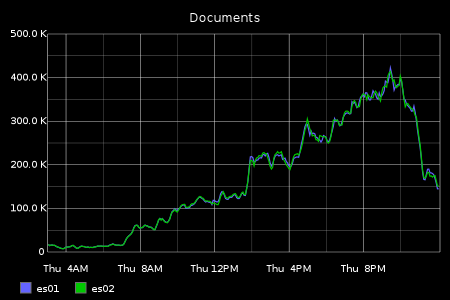
It’s a very modest index size (about 900MB total) – this is the key to serving this off such as a small amount of hardware, since we are only ever keeping a window of 15 minutes of data.
It also leads to the curious situation of our data store size going up and down throughout the daily traffic cycle – not something you would see with a traditional document index!
Future developments
Overall we’ve been very happy with Elasticsearch – it has performed admirably. We’re now looking at implemented some great new features simply not possible before – a full faceted search interface for one.